





Графіка
 Графічний інтерфейс (Qt) для створення, редагування та візуалізації зображень фрактального полум’я flam3 IFS, які можна зберегти як файли png.
Графічний інтерфейс (Qt) для створення, редагування та візуалізації зображень фрактального полум’я flam3 IFS, які можна зберегти як файли png.
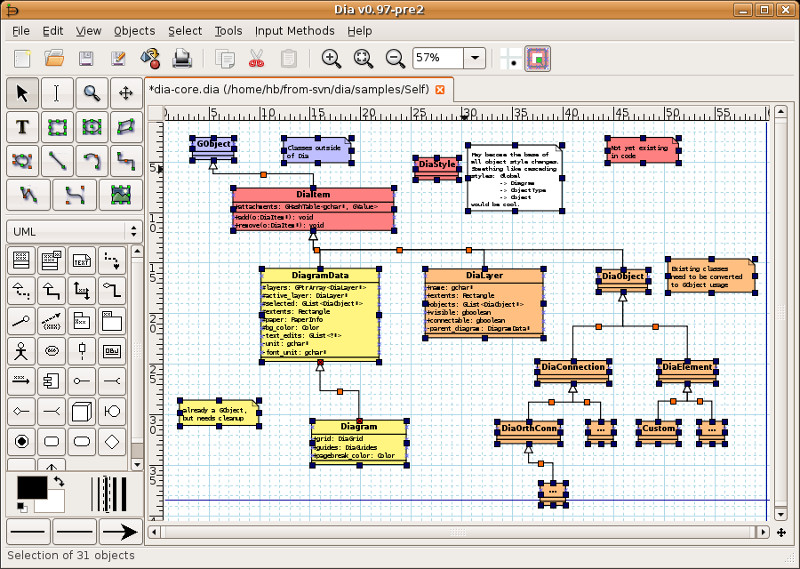 Dia - програма для створення діаграм, графіків, блок-схем і т.д.
Dia - програма для створення діаграм, графіків, блок-схем і т.д.
Є підтримка діаграм статичних структур UML (діаграми класів), діаграм відносин, радіоелектронних елементів, потокових діаграм, мережевих діаграм і багатьох інших.
Dia включає велику кількість графічних елементів для малювання різних схем: блок-схеми, електричні схеми, хімія, Cisco та інші.
Діаграми зберігаються в форматі XML (додатково стискається за допомогою gzip), також підтримується експорт в формати JPEG, EPS , SVG, XFIG, WMF, PNG та інші. В Dia можна імпортувати нові об'єкти, які описуються в XML файлах.
Dia розширювана новими наборами об'єктів, які описуються за допомогою файлів у форматі, заснованому на XML.
Сторінка 7 із 27
ТОВ "УАЛІНУКС"
Написати: - у Viber - у WhatsApp - у Telegram
Зателефонувати: +380 (97) 33-55-1-88 (пн ... пт 10.00 - 17.00) (GMT+2)
E-Mail: [email protected]

![]()
![]()